How Systematic AI Evaluation Actually Works
Most AI teams test their models manually and reactively. It works for prototypes, but once real users depend on the system, that approach breaks over time. You start seeing silent regressions, inconsistent behavior, and bugs that only surface after deployment.
A systematic evaluation framework fixes that. It gives you a predictable way to catch issues before they hit production and a structure that scales as the model changes.
This is the process I use when I build evaluation systems for early-stage AI teams.
1. Turn Failure Modes Into Test Categories
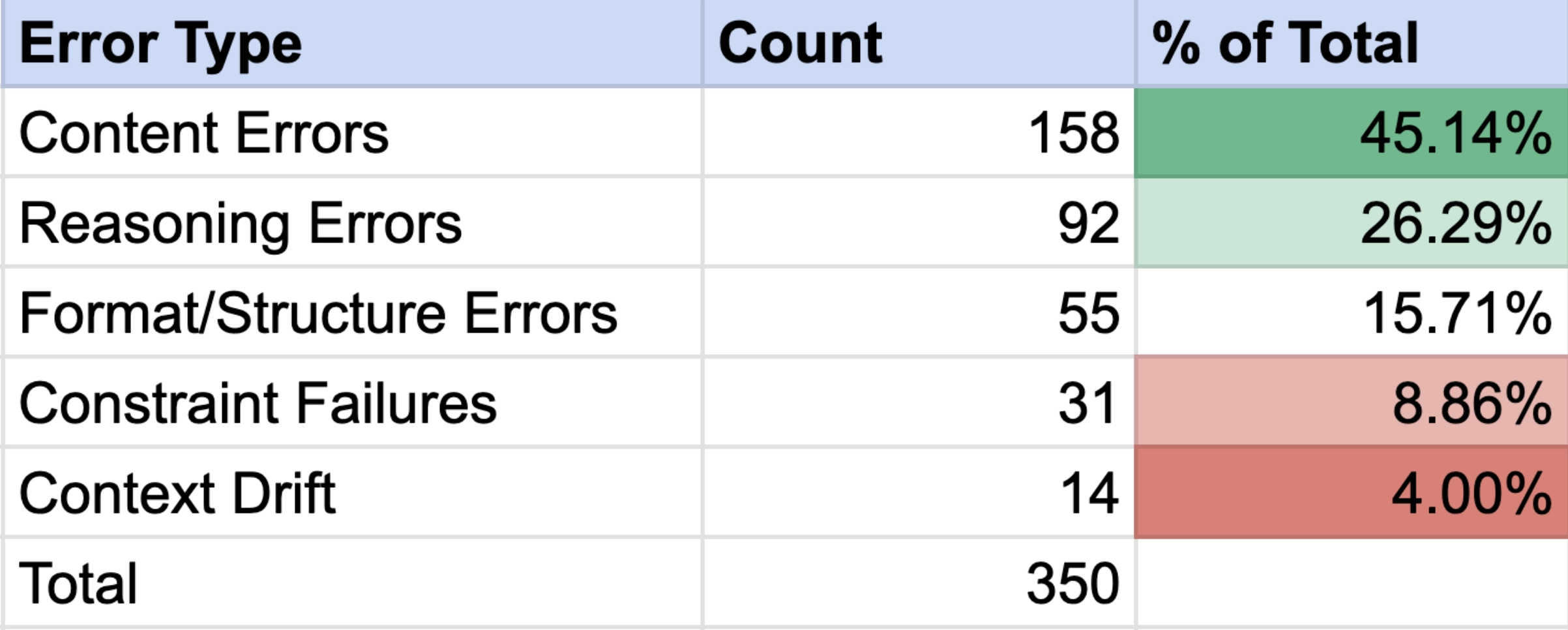
The first step is defining the failure modes. Hallucinations, sourcing errors, reasoning errors, formatting issues, ignoring constraints, losing context, and so on. Teams often skip this step, but without a shared language for failures, you can't define the bugs you're trying to fix.
Once the failure modes are defined, you translate them into a small number of test types: a combination of good examples, tricky edge cases, and regression tests that catch previously observed issues.
You don't need hundreds of prompts, just a compact set of well-designed cases that represent the actual risks in your product.
2. Define Success
Most teams under-specify this. Each test needs a clear definition of what "good" means. Sometimes that's structured validation (checking fields or formats). For open-ended tasks, it's a mix of LLM-as-judge scoring, semantic comparison, and rule-based checks.
The goal is to remove ambiguity: Binary scoring (T/F or Y/N) provides a simple answer. Instead of debating if something's a 7 or an 8, you get a clean, unarguable signal that's actually actionable.
3. Automate the Evaluations
From here, everything becomes mechanical. You set up a runner, batch the tests, run them against the model, and store the outputs and scores. (Braintrust fits well into this stage: versioned datasets, automated scoring, and diff views make iteration easier. But the test logic itself is independent of the tool.)
A systematic eval only matters if every update goes through it first. Before shipping a new prompt, routing change, or model version, you run the tests. If something breaks, you fix it before users ever see it.
This shifts your releases from uncertainty to knowing exactly how the next update behaves.
4. Evolve the Framework as the Product Changes
Once the system is in place, it grows with the product.
User-reported issues become new tests.
New features require new categories.
As the
model improves, you increase thresholds.
This keeps quality in line with what the product is actually doing, not just what you think it's doing.
Opportunities to Automate
Once your evaluation workflow is set up, many parts can run automatically so you catch issues faster and spend less time on manual checks. You can:
- Run tests through the model's API
- Automatically score outputs for correctness or formatting
- Track regressions and flag broken behavior
- Build a simple interface to house these tests, view results, and connect the workflow for a more streamlined process
If you want a framework like this in your product, let's talk.