Ship Reliable
AI Features Faster
Most AI startups ship features that work in demos but fail in production. Edge cases, model inconsistencies, and manual QA costs user trust and slows feature deployments.
Book a Call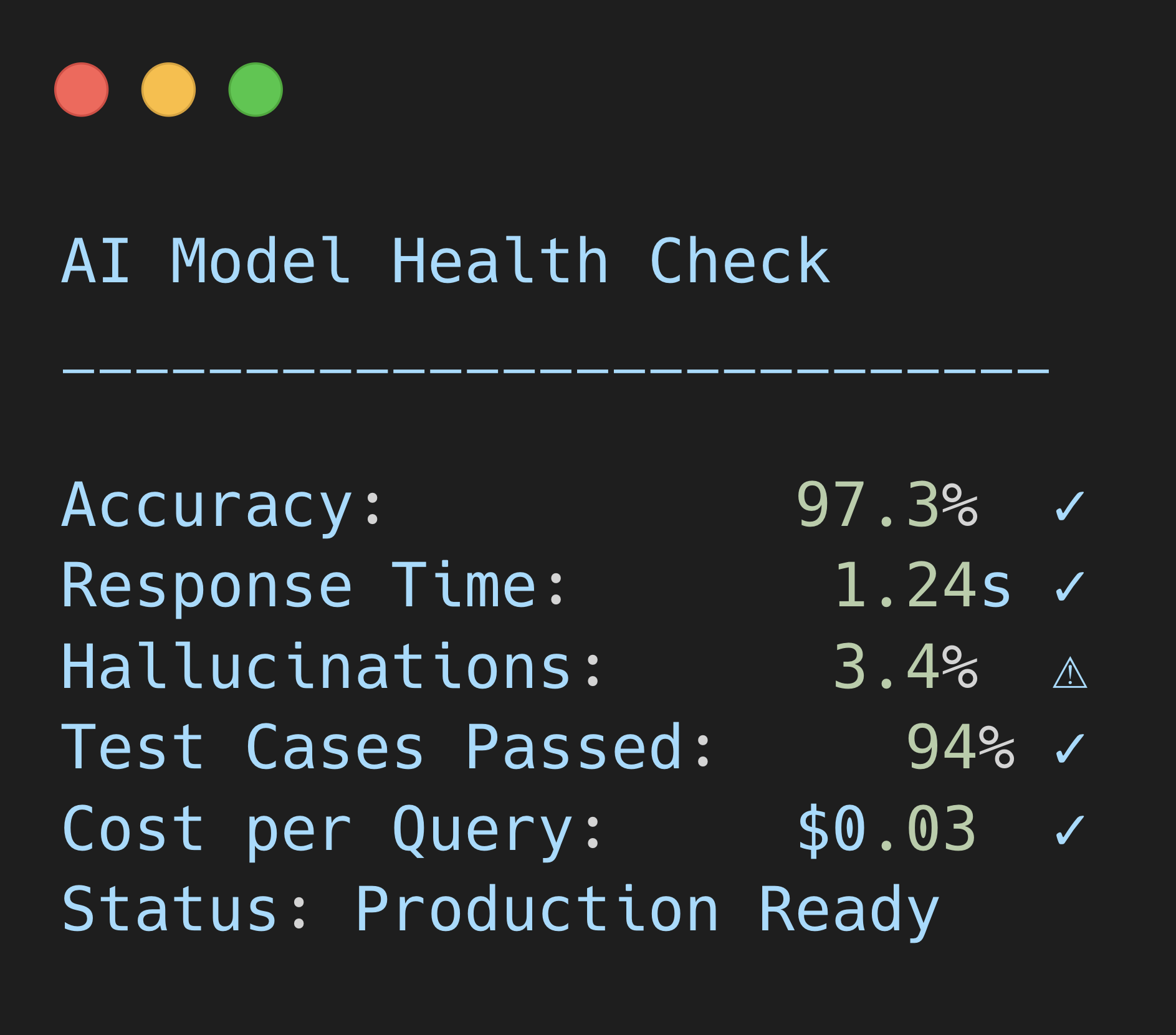
↓


